




Kubernetes(简称K8S)为容器微服务提供了一个基础平台,消除了编排物理/虚拟计算、网络和存储基础设施的负担,并使应用程序运营商和开发人员完全将重点放在以容器为中心的基础上进行自助运营,因此,Kubernetes在各领域的运用越来越普遍。但在我们实际应用的过程中,我们发现Kubernetes集群中各个节点的资源使用率并不均衡,导致在负载很高的主机其上的业务存在运行不稳定,而负载很低的主机资源却被大量浪费。因此,如何实现业务实例的智能调度,使得集群中各节点资源能高效利用,显得越来越重要。
2 K8S的资源调度原理
kube-scheduler 是 K8S 集群的调度器,它的主要功能是为一个新创建出来的 Pod,寻找一个最合适的 Node。kube-scheduler 给一个 Pod 做调度选择包含三个步骤:
过滤(预选):调用一组叫作 Predicate 的调度算法,将所有满足 Pod 调度需求的 Node 选出来,例如,PodFitsResources 过滤函数会检查候选 Node 的可用资源能否满足 Pod 的资源请求。
打分(优选):调用一组叫作 Priority 的调度算法,给每一个可调度 Node 进行打分,例如,LeastRequestedPriority会从备选节点列表中选出Pod request资源消耗最小的节点,然后对各个节点公式打分,最终选取一个得分最高的Node作为优选的结果;
绑定:调度器将 Pod 对象的 nodeName 字段的值,修改为得分最高的 Node。
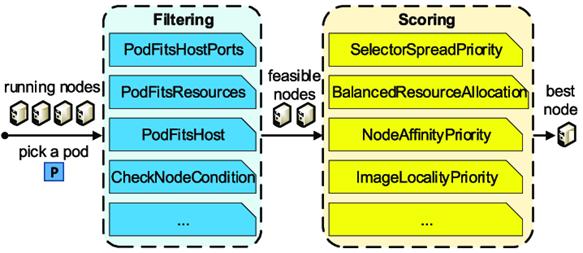
图1 kube-scheduler的基本架构
K8S的最小调度单位是Pod,在创建K8S工作负载的时候,通常需要为工作负载配置合理的CPU、内存的Request和Limit资源,Request值表示创建该工作负载时要求的最低资源,Limit值表示该工作负载运行的最大资源,K8S原生调度器是根据K8S Node的空闲request来进行过滤和打分。但是我们配置Pod request值时,为了能安全启动,往往配置值会比实际程序使用值偏大,这就造成Node已分配的request总和比实际环境的资源利用率偏大。
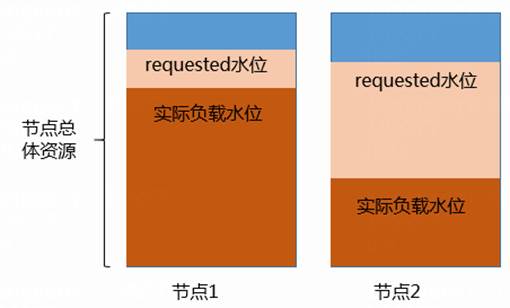
图2 默认调度器下的实际负载水位情况
如上图所示,集群中两个节点间实际资源使用率相差很大,但是每个节点中request值却很接近,正因为这种使用率不均衡的问题无法被K8S原生调度器所感知,新创建的Pod可能仍然会被调度到负载很高的节点1上,带来系统风险,这无疑不是我们所期望的。
下图是K8S官方提供的Pod调度工作流程图,在Kubernetes 1.16 版本开始,K8S的调度框架Scheduling Framework具备了扩展机制,用户可以根据需要对图中每个阶段进行定制开发,实现自定义的调度插件。
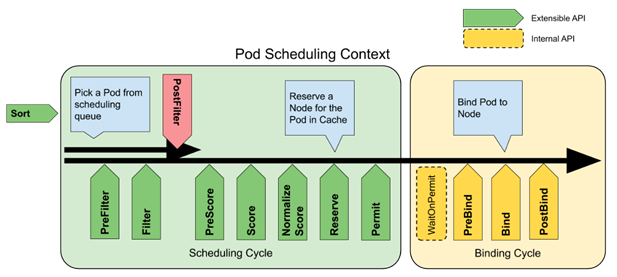
图3. Scheduling Framework的插件扩展机制
K8S社区也提供了一些常用调度插件,如基于实际负载的K8s调度插件Trimaran,该调度插件由指标提供程序(Metrics Provider)、负载检测器(load-watcher)、数据库以及和调度调度算法插件插件组成。
Trimaran集合了TargetLoadPacking和 LoadVariationRiskBalancing调度算法插件。
TargetLoadPacking:它根据节点的实际资源利用率给节点打分,其打分算法其实是数学中的背包问题,采用的best fit近似算法。(支持 CPU 资源。)
oadVariationRiskBalancing:它根据节点资源利用率的平均值和标准差对节点排序。(支持 CPU 和内存资源。)
Trimaran 调度插件的负载检测器(load-watcher)通过监控指标提供程序(Metrics Provider)获取集群内的资源使用指标,如CPU、内存等。目前,负载检测器(load-watcher)支持三个指标提供程序:Kubernetes Metrics Server、Prometheus Server 和 SignalFx。
但是,Trimaran也有其局限性:
(1) Trimaran的调度插件将会与K8S默认的评分插件("NodeResourcesLeastAllocated "和 "NodeResourcesBalancedAllocation ")产生冲突,因此使用时需要关闭默认评分插件。
(2) 节点计算打分的指标维度中没有考虑内存、网络和磁盘等利用率。
(3) 需要预设集群理想值,而实际生产环境存在明显的业务高峰和低谷,没有办法配置一个固定值。
4 业务实例智能调度方法
通正是由于原生调度插件的得局限性过对K8S的资源调度原理和开源调度插件的分析,我们新开发的业务实例调度智能调度器需要能完成如下要求:
• 调度参考指标选择上需要考虑除了CPU、Memory以外,还包括其他关键指标,如磁盘IO、系统工作负载等。
• 获取到节点的历史和当前指标做调度计算依据。
• 获取到被调度Pod的预估资源使用量。
• 根据节点指标和Pod相关指标数据建立一种数学模型,给出集群中各节点的合理得分
• 考虑节点热点问题
• 根据调度计算得分,对负载大的节点上Pod进行驱逐,并尽可能减少业务影响
总体框架
智能调度总体设计方案中由如下部分组成:节点指标数据采集器(Node exporter)、K8S容器指标采集器(cAdvisor)、监控服务(Prometheus)、数据库、调度插件以及均衡调度控制器组成。如下图所示,智能调度的核心在于调度插件,这个插件算法使用Prometheus整合后的指标数据,对节点进行评分。调度插件利用K8S的scheduler-framework的扩展机制,加载到kube Scheduler,实现对K8S集群中业务实例的智能调度。
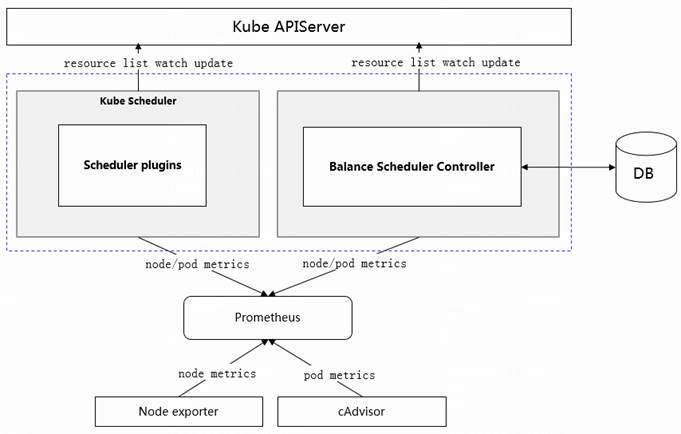
图4. 新型业务实例智能调度器架构
指标的选择和获取
在该方案中,我们采用Prometheus监控方案,通过Node exporter采集节点指标数据,cAdvisor采集容器指标数据,如CPU、内存、网络、磁盘IO和系统负载等指标。Prometheus对采集到的数据进行过滤筛选,对不良数据进行异常处理或补救,指标数据可以在本地进行持久化,并在集群间实现HA,当部分节点数据丢失时,能够快速恢复。通过Prometheus的缓存可以看到过去15分钟、1小时、1天的历史指标数据,并计算均值。
调度插件
这里利用K8S的scheduler-framework的扩展机制,注册定制的基于实时资源使用率的调度插件。该插件主要包括两个模块:
指标获取并注入节点信息模块
该模块通过定时任务从Prometheus的中获取实时资源指标数据,用于接下来的节点调度得分计算,指标包括集群中每个节点的CPU使用量、内存使用量、磁盘IO、工作负载。指标支持用户可配的15分钟、1小时、1天内的数据。
节点调度得分计算模块
获取指标后,根据指标和权重进行节点综合指标打分,K8S调度器通过获取我们定制的调度插件得分进行Pod调度,实现将Pod调度到实际资源使用率较低的节点上。各指标对应的权重支持用户配置。
此外,在实际生产过程中,可能会出现短时间内批量调度大量Pod的情况,比如主机故障重启引起批量Pod迁移,这时候通过Prometheus获取的指标就不准确了,如果不能按照此时的节点使用率去技术计算节点调度得分。对于这种情况,我们需要统计出待调度Pod数量,对集群调度到的节点给出缓冲或熔断动作。
在我们的方案中,通过分析节点在过去N分钟(可配置)调度了超过M个 Pod(可配置),则优选评分减去相应的节点调度得分,从而避免出现短时间大量调度使得调度均衡失效的问题。实现思路:一个Pod从生成到绑定到Node节点上,主要分为两大周期: 调度周期和绑定周期,之前计算节点调度得分过程是调度周期内完成的,Pod 完成调度后,接下来会绑定到节点Node,此时K8S会产生一个Pod的bingding event绑定节点事件,我们可以通过监控Pod的绑定节点bingding event事件,统计1分钟内该节点中新增了多少个Pod的绑定节点事件bingding event,若超过阈值则需要对该节点减去一定的调度得分,从而影响该节点调度优先级,避免出现短时间内批量调度大量Pod的情况。
自动干预,均衡节点资源使用率
业务容器在安装时通过节点实际资源使用率和热点打分进行调度,尽量避免pod requested配置偏大带来的不平衡。当集群中的Pod运行较长时间后,pod的实际资源可能会出现上涨,从而出现个别节点的资源使用率不均衡,Balance scheduler controller通过实时监控节点指标数据,当观测到部分节点的资源使用率较高或者节点故障时,可以自动进行干预,迁移该节点上部分Pod到其他节点上。
自动干预的算法基本思路:
(1)获取每个节点的实际综合使用率,通过CPU使用、内存使用量 、磁盘I/O值、工作负载及其对应的权重进行计算得出
(2)根据每个节点的实际综合使用率,计算出集群的平均综合使用率
(3)找出与集群平均综合使用率偏差最大的节点;并对该节点上的Pod进行驱逐,驱逐前会对Pod先进行过滤,对关键业务pod不进行驱逐,如:
• 要求在指定有节点运行绑定的Pod
• Daemonset类型要求必须Pod要求在每个节点上的存在运行一个至少存在一个的的Pod
• 配置有特殊注解要求不能被驱逐的Pod
• CriticalPod类型的kubernetes框架系统级的Pod
5 小结
1、通过获取历史和当前节点指标值来计算调度得分,能很好地解决因用户配置pod request偏大带来的调度不准确问题,同时我们也加入了对热点节点的预测,并及时进行限流,避免因采集指标后再计算带来调度滞后性问题。
2、自动干预能完成部分节点资源使用率的均衡配置,在调度前,预选出调度优先级,可以更好的提高系统的稳定性。
 浙公网安备 33010802004375号
浙公网安备 33010802004375号
