




当前,人工智能技术在互联网、金融、交通、制造、能源等行业深入应用,在带动人工智能市场规模蓬勃发展的同时,也带来指数级增长的算力需求,计算产业面临着多元化及巨量化的算力挑战。这种挑战对承担算力的基础设施提出了更高的要求。基于此,面向人工智能应用场景的服务器应时而生,它既是实现数字经济时代澎湃算力、海量存储和高速网络的核心驱动器,也必须满足语音识别、图像分类、机器学习、认知推理等多种人工智能业务场景下的算力表现。
一个核心提供强大算力
AI业务需要大量并行计算,目前AI领域最为强大的算力是英伟达Ampere架构的A100 GPU卡。H3C UniServer R5500 G5服务器搭载了具备8张A100 GPU卡的HGX A100 8-GPU模块,在模块内集成6个NVSwitch芯片,实现了GPU模块内600GB/s的高速全互联,对比上代产品算力提升可达20倍。
尽管算力强大,但如何将HGX A100 8-GPU模块引入到服务器端,为人工智能业务提供高效的算力引擎,仍然是让各服务器厂家头疼的问题。尽管NVIDIA给出了DGX A100的参考设计,但当前能够支持HGX A100 8-GPU GPU模块的服务器厂家仍然少之又少,满足NVIDIA参考设计的服务器更是凤毛麟角。

图 1 极致算力的 GPU 模块
三大利器打造强大算力引擎
众所周知,计算、网络、存储是数据中心最核心的三大部分,AI业务同样需要CPU、网络、存储的参与,三者缺一不可,否则会形成计算瓶颈。
灵活选择支持多元化计算平台——R5500 G5在CPU方面设计了双计算平台架构,同时支持AMD和Intel最新的CPU。双CPU平台可以实现无缝切换,即仅需切换计算节点,线缆等其他配置均保持不变,系统PCIe拓扑也不会发生变化,让A100 GPU卡可以自由选择搭档,从而通过灵活选择以满足客户对于不同计算平台的需求。

图 2 支持 Intel、AMD 双平台
多台服务器间网络通信性能飙升——为保证多台服务器之间的网络通信速度,在网络通信设计上,单台R5500 G5服务器通过PCIe Switch分别和8张最高200G的PCIe4.0网卡互连,配合GPU Direct RDMA,使得每张GPU卡都可以直接读取1张200G网卡的数据,网络通信速度最高可提升5~10倍。而当多台R5500 G5搭建服务器集群时,可支持1张GPU卡直接读取1张网卡的数据,极大地提高了多台服务器之间的网络通信速度。
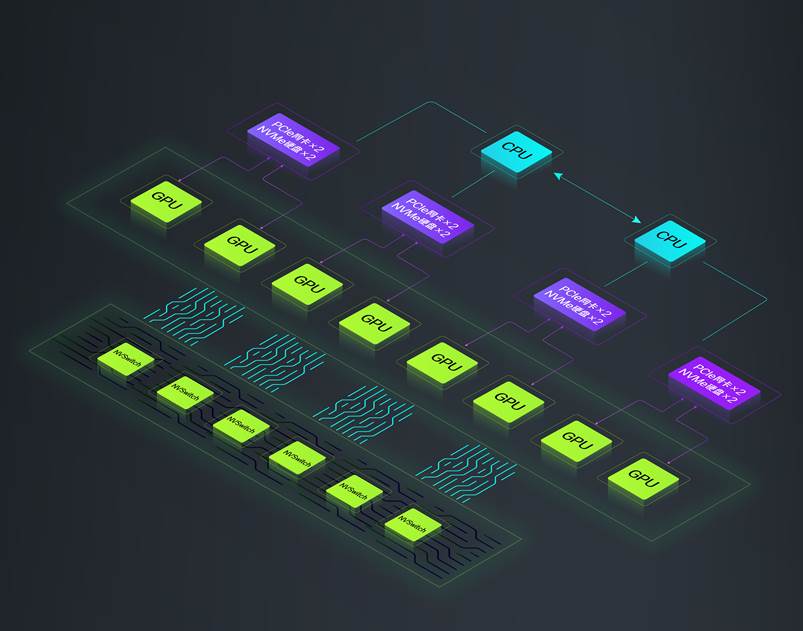
图 3 高速互联的网络拓扑
存储效能匹配AI所需速度——AI服务器集群方案中通常选择后挂高性能的分布式存储,但服务器的本地存储性能也同样重要。尤其是针对AI计算所需要的读写速度时,NVMe硬盘更加适配。R5500 G5服务器采用高性能分布式存储,最多可支持25个2.5英寸硬盘,其中最高支持12个NVMe硬盘。12个NVMe硬盘中,有8个硬盘是通过4个PCIe Switch直接与GPU互联。和GPU直连网卡类似,配合GPU Dierct Storge功能,GPU可直接通过PCIe Switch读取NVMe硬盘的数据,无需通过CPU中转,读写效率获得了数倍的提升。

图 4 强大的存储扩展能力
软硬结合 构建强大AI集群
硬件只是AI集群建设的一部分,如何让用户对服务器进行全流程可视化管理,才是释放AI算力的关键。通过软件层面的深度优化,R5500 G5服务器以软硬结合的方式,为AI开发提供集群监管/作业调度/AI建模/分区管理/HPC作业等功能,计算的效率实现了大幅提升。
得益于容器化的软件架构,R5500 G5服务器所提供的计算资源可以被集中管理、统一分配与作业调度,包括实现GPU资源池的集中管理与分配、多租户方式隔离计算资源、以作业方式动态分配计算资源以及计算资源回收等功能。用户会实时监控管理集群资源使用情况和集群状态,包括作业状态、GPU使用率、集群健康度等。
R5500 G5服务器所匹配的丰富集群配置、管理工具,让集群管理更加方便快捷。通过图形化的一站式交互开发操作界面,帮助用户完成模型脚本在线编辑、模型训练、模型验证以及模型推理等核心功能,并结合硬件资源可视化、作业调度器,最大化提高系统硬件资源的利用率。
纵观市场上的人工智能优化服务器产品,H3C UniServer R5500 G5服务器是一款跨时代的服务器产品。性能的AI硬件平台建设奠定了坚实基础。目前,众多互联网企业、AI企业、科研机构等行业客户已经将R5500 G5服务器用于AI开发。未来,R5500 G5将会在更多场景下加速各行各业AI的应用和落地。
 浙公网安备 33010802004375号
浙公网安备 33010802004375号
