




摘要:日志解析是支撑对日志进行深入分析从而发现异常和定位故障原因的第一步。通过日志解析提取出日志中关键的有效信息,为挖掘日志的重大价值提供了基础。
日志记录在ICT系统中十分普遍,有研究者调查发现,系统实现代码中平均每30行代码中就有一行是日志。日志记录了ICT系统详细的运行信息,是监测系统状态、发现异常和定位故障原因的重要参考依据,对于管理保障系统的稳定可靠运行有重大意义。
由于日志是自由文本形式的非结构化数据,所以通过日志解析将非结构化数据转化为结构化数据是挖掘日志价值的第一步。将日志解析出来进行存储后,就可以全文搜索和直观展示,经过分析和推理,可以实施异常检测、故障定位、行为分析和态势分析。如图1所示。
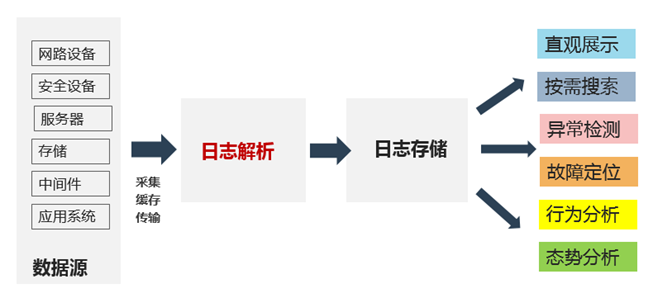
图1 日志解析在日志处理流程中的位置
日志解析现有方法和遇到的问题
日志解析的任务是将原始的自由文本日志消息转换为结构化的信息。从图2所举例的日志消息可以看出,日志消息记录了系统事件,原始的日志消息一般由消息头和消息内容构成,消息头可以包括时间戳、给出消息的系统模块、错误级别、错误类型等信息,消息内容由常量字符串和变量值组成。日志解析的目标就是区分出常量表达和表示动态运行参数的变量表达,识别并给出原始自由文本日志消息中所蕴含的日志事件模板,借助日志事件模板实现最终的结构化日志消息转换。

图2 日志解析实现原始消息的结构化转换
日志解析目前最常用的方法是通过人工预置规则的方法,即根据已知的日志事件模板,通过编写从自由文本中提取常量和变量参数的正则表达式实现。现在有日志处理软件提供专门的工具定义相关的正则表达式,比如,流行的开源软件ELK以Grok模式提供方便的以文本模式定义正则表达式的方法。人工编写和维护日志提取规则是非常有效准确的方法,也正是这个原因,使其成为目前主流的日志解析方法。
但是人工解析规则正在逐渐变得难以管理。首先,软件系统是不断更新升级的,软件系统的发展变化导致日志结构的频繁变化。据统计,日志代码的修改更新率比其它代码要快约一倍,其中,约四分之一的修改是增加新变量,约一半的修改是对日志消息静态文本的修改。其次,随着时间的推移,不断有新的功能或者新的设备系统和型号需要管理,解析规则需要相应持续增加。另外,人工逐个编写解析规则是很费时的工作。因此,在系统变化慢和规模也不够大的时候,全部依赖人力能够完成,但当涉及的解析规则由几十个、几百个,增加到成千上万个时,这项工作就成为比较大的负担,促使业界开始寻找扩展性更好、且自动化解析的方法。
有人探索了从源代码中提取日志事件模板的静态分析技术,这种技术在可以访问源代码的情况下有意义,但对于更普遍存在的没有权限访问源代码的情况就不适用了。随着人工智能技术的发展,业界探索的目光开始投向基于数据驱动的智能日志解析方法。
基于数据驱动的智能日志解析方法
为了实现基于数据驱动的智能自动日志解析,业界提出多种方法,典型的有以下两大类算法:
1. 频繁模式挖掘算法 (Frequent PatternMining)
频繁模式就是“经常一起出现”的模式,是数据挖掘中很常用的一种挖掘。著名的“啤酒与尿布”的故事是一个典型例子。在有婴儿的家庭中,年轻的父亲前去超市购买尿布时,常会顺便为自己购买啤酒,使得看上去不相干的啤酒与尿布经常会出现在同一个购物篮。沃尔玛超市发现这一现象,将啤酒与尿布摆放在同一区域,让客户一次购买到两件商品,从而获得了很好的商品销售收入,这就是“啤酒与尿布”故事的由来。频繁模式挖掘就是要找出这些频繁出现的模式。对于日志解析来说,其中的常量字符串就是频繁一起出现的分词项,把一条日志中的所有常量字符串找出来后,剩下的部分就是变量字符串,从而识别出该条日志的常量和变量参数。
目前这类方法的解析过程一般为:多次遍历日志数据,在每次遍历时构建频繁项集,逐渐形成多个集群,将日志消息分组到多个集群中,从每个集群中提取日志事件模板。由于需要使用日志集中的大量数据来多次遍历统计频繁项,目前这种方法一般采用离线分析的方式。这种方法面临的挑战是对词项位置移动具有健壮性的日志,以及罕见日志的解析。
2. 聚类算法(Clustering)
每一种日志,或者说最后总结出的每个日志事件模板,可以看作是一个类别。当大量日志来临时,如果能判断出每一条日志的归类,就识别出了其所属的日志事件模板。因此,日志的解析可以看作是一种聚类问题。
应用聚类算法进行日志解析的探索,有离线和在线两种方式。具体来说,目前业界有以下聚类解析的方法:
1) 离线聚类算法
线下对日志进行处理解析,具体包括基于成对日志消息之间加权编辑距离的层次聚类算法、基于消息签名将日志消息聚类到预定义的集群中的算法、基于分层集群的方式生成事件模板,将日志消息从下到上分组到集群中等算法。
2) 在线聚类算法
线上以流方式解析日志。对于每个到来的日志消息,计算其与现有日志集群的代表性事件模板的相似性。如果成功匹配,日志消息将被添加到现有集群中,否则将创建一个新的日志集群,其相应的事件模板也会随之更新。此类解析方法会在聚类过程中利用日志消息的独特特征。首先根据日志消息的特性,利用先验知识对日志进行预处理,比如用简单的正则规则把日志中经常出现的IP地址识别出来,从而增加解析的准确性。然后采用固定深度的树结构有效分类和提取常见模板,基于相同日志事件包含的词项数目相同的假设,将日志根据长度进行根节点下第一层叶子节点的分类,然后再计算分词项与现有日志组集合的相似度,如果找到相似度满足域值的则归入该日志组,否则新建一个日志组。由于利用了日志特性,该方法在很多情况下表现较好。
结束语
由于日志解析是实现自动化日志分析的第一步,因此在ICT系统维护中扮演着重要的角色。伴随日志规模在种类、数目上的增多,日志更新的加快,致力于日志智能自动解析的研究越来越多。但目前该方向还处于探索期,在工业界尚未得到广泛应用,后续在日志数据集的搜集、日志的预处理、变长与罕见日志的解析等多方面仍需要付出更多的努力。道路曲折,但前途光明,相信综合各种有效方法之长,日志解析的智能自动化程度会越来越高,并逐渐实现在工业界的落地。
 浙公网安备 33010802004375号
浙公网安备 33010802004375号
