




摘要:通过对输入样本进行细微的修改,人眼不易觉察,但却使AI系统产生错误的输出,在一些关键场景中会造成严重问题,当下备受关注的对抗样本攻击与防御旨在预防这类攻击。
随着人工智能应用日趋普及,我们在生活中已经能切身感受到人工智能带来的便利,从虚拟语音助手到自动驾驶汽车。但随之而来的是人工智能应用自身的安全问题逐渐显露,AI安全也被提上日程。
据新闻报道,在2019年,腾讯科恩实验室曾对特斯拉车型所搭载自动驾驶系统(2018年的某个版本)进行安全性测试,发现其在图像识别方面,存在被攻击的安全隐患。例如,在大多数情况下,自动驾驶系统都能正常识别交通标志、标线,但实验中,如果在路面涂刷不起眼的干扰信息,车辆根据看到的图像,却做出了错误的决策,车辆直接驶入反向车道。
虽然这些安全测试是在实验室中进行的,但试想一下,如果在现实生活中,这些针对人工智能应用的攻击方法被恶意使用,后果将不堪设想。所以人工智能应用的安全问题,直接关系到人工智能的生态繁荣,是学术界和工业界的重点研究技术方向之一。
AI应用面临的安全挑战
当前主流的人工智能应用,多数是基于传统机器学习或深度学习算法开发的,从开发到生产部署,一般有数据采集、数据预处理、模型训练、模型的评估验证、生产部署等几个环节,如图1所示。
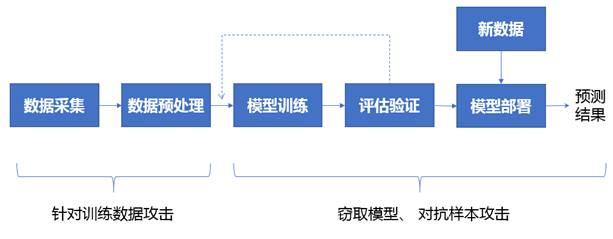
图1 AI应用的各环节及攻击点
黑客针对人工智能应用进行攻击,多数也存在于这几个环节,大体上分为三种情况:
1.针对数据采集和预处理阶段的攻击
数据噪声、数据污染会带来人工智能安全问题。人工智能训练模型时用到的训练数据,如果数据本身含有较大的噪声,或者数据受到人为破坏,都可能会导致模型决策出现错误。由于一些客观因素,训练数据中不可避免含有噪声,如果算法模型处理地不得当,可能会导致模型漏洞,模型不够健壮,给黑客有了可乘之机。另外,黑客故意在训练数据中植入恶意数据样本,引起数据分布的改变,导致训练出来的AI模型决策出现偏差,进而按照黑客的意图来执行,例如微软早些年推出的聊天机器人,上线24小时就被教坏了,满嘴脏话,原因就是与用户对答的“不良数据”被混入到了语料库中所致。
严格限制数据的访问和使用权限,限制用户提交用于训练模型的数据量,在一定程度上可以降低这方面的风险。
2.针对AI模型本身
通常针对AI模型本身的窃取,有两种可能途径:一种是由于系统或平台的漏洞,导致黑客可能会获取足够的权限,直接窃取AI模型本身或源代码;另一种途径是针对AI开放平台上部署的视觉类、语音类等AI算法模型,黑客通过不断地尝试查询被攻击系统的输出接口,利用返回来的信息来构建和训练黑客自己的AI模型,从而达到仿造AI模型的目的,然后基于仿造的AI模型进行研究和分析。虽然这种方式仿造出来的模型在二进制层面上和原始模型是不同的,但是仍然是存在一定风险的。
经常检查日志,对异常访问情况提高防范,一定程度上能减少模型的失窃风险。
3.针对模型使用环节的对抗样本攻击
当前主流的深度学习算法的鲁棒性还存在问题,非常容易受到对抗样本的攻击的。一些图像或语音的对抗样本,仅有很轻微的扰动,以至于人类无法察觉这种扰动。但对于AI模型却很容易觉察并放大这个扰动,进而输出错误的结果。
针对各种对抗样本的攻击,已经有了多种防范方法来降低风险。下文将重点针对AI对抗样本攻击与防护的技术展开探讨。
AI对抗攻击与防御技术
对抗样本攻击与防御是近几年人工智能领域的研究热点之一,每年的人工智能会议上都会有一些新的成果发表,这里我们重点介绍一些基础原理。
1.什么是对抗样本攻击
对抗样本(Adversarial Examples)的概念最早是Christian Szegedy等人在论文《Intriguing properties of neural networks》中提出来的,也即通过对输入样本添加一些非随机性的微小扰动,受干扰之后的输入样本经过AI模型运算,会导致模型以高置信度给出了一个错误的输出结果。
如图2所示,一张原本是熊猫的图片,在加入了人为设计的微小噪声扰动后,人眼看上去还是熊猫,但AI模型直接将其识别为长臂猿,且可信度高达99.3%。

图2 对抗样本
当然,还有另外一种对抗样本,样本图像是人类无法看懂的,但AI模型却高概率认为是某个类别的事物。
如图3所示,直接针对噪声进行编码或者间接编码,形成的对人类无法看得懂的噪声样本(Fooling Examples),深度学习模型却会以99.99%置信度识别为0-9的数字。

图3 另类对抗样本
(1)不止是深度学习所特有
近几年很多对抗样本攻击的研究都是针对深度学习模型展开的,其实有研究表明,不止是深度学习模型对对抗样本表现出脆弱性,传统的一些机器学习算法如SVM(支持向量机)、决策树等算法,当通过人为精心设计的方法,改变少许特征,对人来说很难察觉,但对算法模型来说,内部经过多级放大,最后也会产生错误的结果。所以,对抗样本攻击不是单独针对深度学习算法的,传统机器学习算法也存在该问题。
(2)针对物理世界的攻击
前面提到的对抗样本图像,都是在数字世界中进行的,其实有些对抗样本的泛化性能还是比较强的。
伯克利大学在《Robust Physical-World Attacks on Deep Learning Models》论文中做过实验,针对自动驾驶中的交通标志识别模型,实验中是在一个红色的“STOP”标志上,贴上一些通过精心设计的贴纸,这时对于人类依然能够正确识别出交通标志,但却会导致AI模型失效,无法识别出“STOP”标志,或者识别为其他类别的标志。

图4 交通标志上叠加干扰贴纸
另外,在ECCV 2020大会上,有一篇论文研究的就是基于对抗样本技术来设计体恤衫,表面印有特殊的图案,穿戴者可以轻松躲避AI目标检测系统,使其无法检测出人体。
(3)音频和文本识别也存在对抗样本
对抗样本最早是在图像领域中研究的比较多,针对一些卷积神经网络模型进行的,但是在音频识别和文本识别当中,也存在类似的问题。
例如在进行语音识别过程中,如果此时背景音乐是经过精心设计的,那么就有可能使识别结果错误,甚至按照攻击者的意图来输出结果。
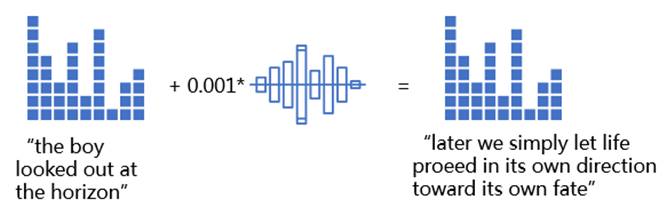
图5 语音对抗样本
在文本处理任务中,也存在类似的问题,在文本段落中,增加一些特殊的词汇或标点,或者在不改变语义情况下调整个别句子,人类不易察觉,但AI模型却无法按照预期输出正确的结果。
(4)对抗样本的正面应用
前面说了那么多的对抗样本的负面应用,其实合理的使用该技术,也能产生正向的价值。
我们日常生活中经常接触到的验证码机制,就是为了保证系统安全操作而设置的。但是在一些黑色产业链中,利用AI技术让机器识别验证码来谋取利益,比如在春运的抢火车票或者破解一些系统的登录环节,增加了商业系统的安全风险。
这时可以采用对抗样本的技术,在正常的验证码图片上,增加少许精心设计的扰动,这些扰动不足以干扰正常用户的识别,但却可以让黑灰产业的AI验证码识别模型的识别率大幅下降。

图6 对抗验证码
(5)对抗样本攻击的分类
在技术层面上,按照对抗样本的实现方式主要分为白盒攻击和黑盒攻击两类。
白盒攻击:攻击者完全了解被攻击的AI模型的结构、源码、训练数据集等信息,可以实施更加精确的攻击,难度较低,多用于学术研究。常见的白盒攻击算法如L-BFGS、FGSM、BIM、ILCM、DeepFool等。
黑盒攻击:攻击者对AI模型和训练数据集的信息了解得不多或者完全不了解。但利用对抗样本具有跨模型、跨数据集迁移的泛化能力,研究被攻击AI模型的输入/输出信息,设计对抗样本进行攻击,这种方式的实现难度比较大。黑盒攻击比较有名的是在论文《One pixel attack for fooling deep neural networks》中,曾提出一种单像素攻击方法,利用差分进化的方法,只修改一幅图像的少数像素点(如1个、3个或5个像素),就可以直接戳中要害实施攻击,导致模型输出错误结果。
另外,按照从攻击目标输出结果的维度,可以分为:
非针对性攻击(non-target attack):让AI模型输出结果出错即可。
针对性攻击(targeted attack):不仅让模型输出结果错误,而且还要让其输出结果按照攻击者预定的结果来输出。
2.对抗样本的生成机理
通俗来讲,对抗样本的基本原理就是在原始样本上叠加人类难以觉察的细微扰动,让AI模型产生错误的输出。近几年的学术研究中,生成对抗样本的方法有很多种,最为经典的就是早年间Goodfellow在《Explaining and Harnessing Adversarial Examples》论文中提出的FGSM算法(Fast Gradient Sign Method)。
以图2为例,假设输入的原始熊猫图像为x,识别结果为y,叠加的噪声用η表示,那么对抗样本x ̃为:
x ̃=x+η
论文中指出,噪声η的取值为:
η=ϵsign(∇_x J(θ,x,y))
其中,θ为模型参数,x为输入图像,y为模型输出结果,J(θ,x,y)为定义的损失函数,sign(*)为符号函数。
我们以前是用大量数据来训练AI模型,也就是是通过梯度下降法,不断朝着梯度的反方向迭代,调整模型参数θ直到收敛。而在这里在生成对抗样本的时候,是在保持模型参数θ不变,通过设置η扰动为沿着梯度方向的微小增量,从而达到放大损失函数误差的目的(即输出结果偏离正确结果),进而得到可以导致模型出错的对抗样本。
当然,也有些文献中提出的算法可以实现针对性攻击,主要是对损失函数J(θ,x,y)做改进实现的。构建的损失函数一般由两部分组成,一部分表达的是对抗样本与目标样本的相似度差距,另一部分表达的是对抗样本的预测误差。使用这样的损失函数来对对抗样本x ̃进行迭代,迫使对抗样本的输出朝着指定预测结果靠拢,而且又要保证样本x ̃长得像目标样本,例如在图2中,既要使得对抗样本长得像熊猫,也要使模型输出长臂猿的标签。
3.对抗攻击的防御方法
前面主要描述的是对抗样本的生成方法,那么对于对抗样本攻击的防御也是学术界和工业界重点研究的方向。
对于对抗样本进行分析,尤其是图像样本,经过放大后还是可以观察到一些细微的噪声,导致图像细节有些变化。因此,很自然的想法就是在图像输入到AI模型之前,先进行图像滤波、去噪的预处理,将图像进行一定程度的修复还原,起到一定程度的防御作用。
另外一种思路,就是可以将各种类型的对抗样本增加到AI模型训练数据集中,这样训练出来的模型,先天就对部分AI对抗样本具有免疫功能,一定程度上提高系统的鲁棒性,但对抗样本的生成方法层出不穷,难以收集完备的对抗样本数据集。
还有一些方法是通过修改AI模型的网络结构,达到抵抗攻击的目的,感兴的趣读者可以阅读相关文献。
结束语
AI应用安全的问题,直接关系到AI应用在各行业领域的推广,对抗样本攻击是AI安全的一个重要方向,越来越引起学术界和工业界的重视。目前面向AI应用的攻击和防护的研究还处于初级阶段。未来,通过广大科研工作者的努力,相信会厘清对抗攻击方法的背后机理,最终可以形成一种统一高效的防御体系,为AI生态保驾护航。
 浙公网安备 33010802004375号
浙公网安备 33010802004375号
